
Im vierten Teil der Serie wurde deutlich: Cloud ist nicht gleich Cloud. Zwischen einfacher API-Nutzung, kontrollierten Cloud-Setups, souveränen Betriebsmodellen und On-Premises-Lösungen liegen große Unterschiede.
Doch wie entscheiden Unternehmen auf dieser Grundlage, welches KI-Setup überhaupt zu ihrem Anwendungsfall passt?
Viele KI-Diskussionen beginnen dabei an der falschen Stelle. Häufig wird früh darüber gesprochen, welches Modell eingesetzt werden soll oder welche Technologie aktuell als besonders leistungsfähig gilt. Die eigentliche Herausforderung liegt jedoch oft früher: Welche Anforderungen stellt der konkrete Use Case an Datenverarbeitung, Kontrolle und Betrieb?
Denn nicht jede KI-Anwendung braucht dieselben Rahmenbedingungen. Je nach Sensibilität der Daten, Governance-Anforderungen und gewünschtem Kontrollniveau verändern sich auch die Anforderungen an Setup und Modellauswahl.
Dieser Beitrag zeigt, warum Unternehmen bei der Auswahl von KI-Lösungen nicht mit dem Modell starten sollten, sondern mit dem Anwendungsfall und weshalb genau daraus die entscheidenden Architektur- und Betriebsfragen entstehen.
Der Use Case bestimmt den Entscheidungsraum
Die entscheidende Frage bei der Auswahl von KI-Systemen lautet häufig nicht, welches Modell aktuell die höchste Leistungsfähigkeit erreicht. Wesentlich relevanter ist zunächst, welche Aufgaben die KI konkret übernehmen soll, welche Daten verarbeitet werden und unter welchen Rahmenbedingungen der Betrieb erfolgen muss.
Denn daraus ergibt sich, welche Form der Infrastruktur überhaupt sinnvoll ist – von einfachen Cloud-Setups über kontrollierte Betriebsmodelle bis hin zu souveränen oder On-Premises-nahen Architekturen. Erst auf dieser Grundlage lässt sich beurteilen, welche Modelle technisch, organisatorisch und regulatorisch sinnvoll eingesetzt werden können.
Drei zentrale Fragen helfen dabei, diesen Entscheidungsraum systematisch einzugrenzen:
1. Werden sensible Daten verarbeitet?
Wenn keine sensiblen Daten betroffen sind, kann ein einfaches Cloud-Setup oder die Nutzung eines Model as a Service (MaaS) ausreichen. Dabei werden Modelle über die Infrastruktur eines externen Anbieters genutzt, ohne dass eigene Systeme betrieben werden müssen. Für frühe Experimente oder Anwendungsfälle mit geringem Risiko stehen hier meist Geschwindigkeit, einfache Integration und geringer Betriebsaufwand im Vordergrund.
2. Müssen Daten unter eigener Kontrolle bleiben?
Sobald sensible, interne oder regulatorisch relevante Daten verarbeitet werden, reicht es nicht mehr aus, nur auf Modellqualität zu schauen. Entscheidend wird, wo Daten verarbeitet werden und wie gut sich der Betrieb kontrollieren lässt. Unternehmen trennen Datenpfade bewusster, definieren klarere Governance-Regeln und prüfen kontrollierte Cloud-Setups (EU Data Boundary / DE/EU Provider / Sovereign Cloud) oder Open-Source-Modelle. Für viele ist dieses Zielbild langfristig der realistische Zielzustand, weil es Skalierbarkeit und Steuerbarkeit miteinander verbindet.
3. Wie hoch ist der Souveränitätsbedarf?
Je kritischer der Use Case, desto wichtiger werden Datenkontrolle, Nachweisbarkeit, Eigentum an Artefakten und Unabhängigkeit von einzelnen Anbietern. Für besonders sensible oder regulierte Anwendungsfälle führt das häufig zu privaten oder On-Premises-nahen Betriebsformen, bei denen Infrastruktur und Datenverarbeitung weitgehend unter eigener Kontrolle bleiben, allerdings auch mit höherem Betriebs- und Integrationsaufwand.
Diese Reihenfolge ist wichtig, weil sie verhindert, dass Unternehmen zuerst ein Modell auswählen und anschließend versuchen, Sicherheit und Governance nachträglich darum herumzubauen.
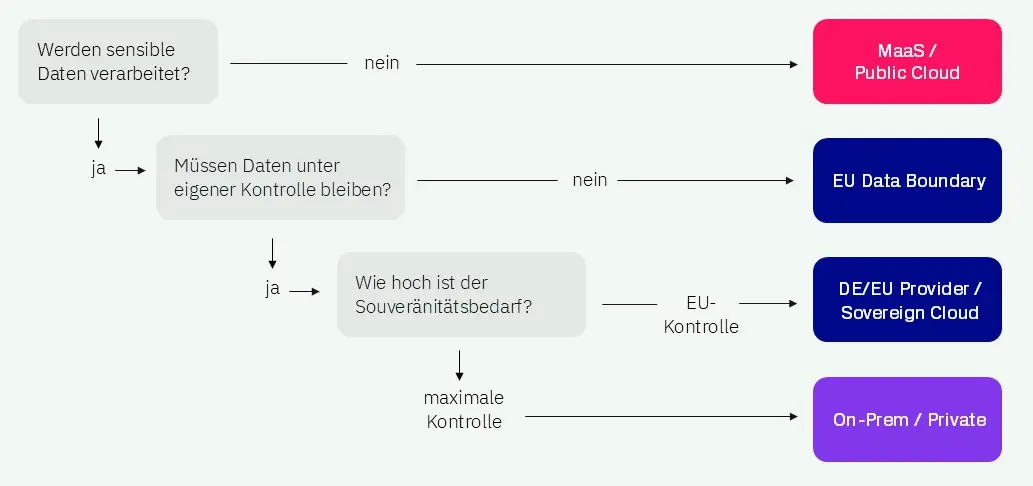
Abbildung 1: Entscheidungsbaum für KI-Infrastruktur und Modellauswahl
Betriebsmodell und Modellauswahl hängen direkt zusammen
Die Anforderungen an Kontrolle, Governance und Datenverarbeitung wirken sich unmittelbar auf Betriebsmodell und Modellauswahl aus. Grundsätzlich lassen sich dabei zwei zentrale Betriebsformen unterscheiden: Cloud und On-Premises.
Beim Cloud-Betrieb wird die Infrastruktur von einem externen Anbieter bereitgestellt und über das Internet genutzt. Unternehmen profitieren hier vor allem von schneller Verfügbarkeit, hoher Skalierbarkeit und geringem Betriebsaufwand.
On-Premises bedeutet dagegen, dass Modelle auf eigener Infrastruktur betrieben werden. Dadurch bleiben Daten, Kontrolle und Governance vollständig im eigenen Haus, allerdings zu höheren Investitions- und Betriebskosten.
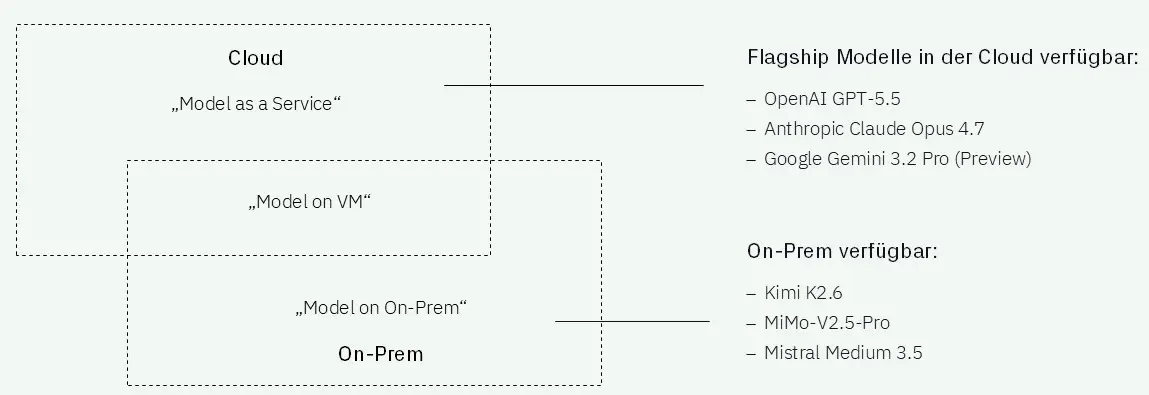
Abbildung 1: Zusammenhang von Betriebsform und Modellauswahl
Innerhalb dieser Betriebsformen existieren unterschiedliche Modellansätze. Flagship-Modelle wie OpenAI GPT-5.5, Claude Opus 4.7 oder Gemini 3.2 Pro werden heute nahezu ausschließlich als sogenannte Model-as-a-Service-Angebote (MaaS) genutzt. Die Modelle laufen dabei vollständig in der Infrastruktur des jeweiligen Anbieters und werden über APIs eingebunden. Unternehmen müssen sich dadurch weder um Hosting noch um Skalierung oder Modellpflege kümmern.
Demgegenüber stehen Open-Source-Modelle wie Kimi K2.6, MiMo-V2.5-Pro oder Mistral Medium 3.5. Deren Gewichte sind frei verfügbar, sodass Unternehmen die Modelle selbst betreiben, anpassen und stärker in eigene Architekturen integrieren können. Dadurch entstehen mehr Flexibilität und Kontrolle, allerdings auch höhere Anforderungen an Betrieb und technisches Know-how.
Zwischen diesen Polen liegt der Betrieb von Open-Source-Modellen auf virtuellen Maschinen in der Cloud („Model on VM“). Dieser Ansatz kombiniert die Flexibilität eigener Modelle mit der Skalierbarkeit externer Infrastruktur und reduziert gleichzeitig die Abhängigkeit von proprietären MaaS-Angeboten.
Für klar abgegrenzte Aufgaben wie interne Wissensassistenten, dokumentenbasierte Analyse, Vertragsprüfung oder RAG-Szenarien können lokal oder kontrolliert betriebene Modelle deshalb besonders sinnvoll sein. Allerdings bleibt die Auswahl leistungsfähiger Modelle außerhalb großer Cloud-Angebote derzeit deutlich eingeschränkter.
Entscheidend ist daher nicht immer das leistungsstärkste Modell am Markt, sondern das passendste für den konkreten Use Case. Dies hat aber deutliche Implikationen auf die Qualität der zur Verfügung stehenden Modelle. Wie Abbildung 2 (schwarze Markierungen = Cloud, blaue Markierungen = Open Source) zeigt, befinden sich unter den Top 10 der aktuell besten Modelle nur zwei Modelle, die als Open Source Varianten verfügbar sind. Und diese belegen erst die Plätze sechs und sieben. Weiter hinten in der Liste (auf Rang 19) kommt mit Mistral Medim 3.5 das erste europäische und gleichzeitig das erste europäische Open Source Modell – mit einem Score, der deutlich hinter den US-amerikanischen und chinesischen Modellen hinterherhinkt.
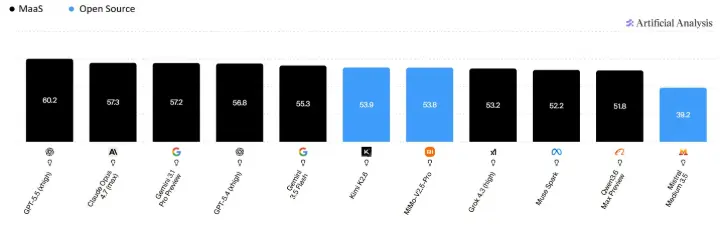
Abbildung 3: Vergleich der leistungsstärksten KI-Modelle gemäß dem Artificial Analysis Intelligence Index. Quelle: Artificial Analysis (2026), abrufbar unter: https://artificialanalysis.ai/
Typische Fehler bei der Modellauswahl
Ein häufiger Fehler besteht darin, ein einziges KI-Setup für alle Anwendungsfälle im Unternehmen etablieren zu wollen. Das ist meist nicht sinnvoll.
Ein Marketing-Use-Case mit unkritischen Texten braucht nicht dasselbe Betriebsmodell wie eine Vertragsprüfung mit sensiblen Dokumenten oder ein KI-System in einem regulierten Umfeld.
Ein zweiter Fehler ist die Überbewertung von Benchmarks. Ein Modell kann auf dem Papier sehr leistungsfähig sein und trotzdem nicht zum konkreten Prozess passen. Entscheidend ist nicht nur die Modellqualität, sondern auch die Frage, ob das Modell sicher, kontrolliert und wirtschaftlich betrieben werden kann.
Ein dritter Fehler liegt darin, Exit-Fähigkeit und Portabilität zu spät zu berücksichtigen. Wer heute eine Plattform- oder Modellentscheidung trifft, schafft damit oft langfristige Abhängigkeiten. Deshalb sollte früh geprüft werden, wie leicht ein Modell gewechselt, ergänzt oder in eine andere Architektur überführt werden kann
Checkliste: So kommen Unternehmen zur passenden Modellauswahl
Ein praxistauglicher Auswahlrahmen umfasst sechs Schritte:
- Use
Case klären
Was soll die KI konkret tun und in welchen Prozess wird sie eingebunden? - Daten
klassifizieren
Welche Daten werden verarbeitet und wie sensibel sind sie? - Kontrollbedarf
bestimmen
Welche Anforderungen bestehen an Nachvollziehbarkeit, Eingriffsmöglichkeiten und Verantwortung? - Betriebsmodell
auswählen
Reicht eine API-Nutzung oder braucht es kontrollierte Cloud-, souveräne oder private Betriebsformen? - Modellklasse
bestimmen
Kommt ein Frontier-Modell, ein Open-Weight-Modell oder ein lokal betreibbares Modell infrage? - Pilotieren
und messen
Nicht das bekannteste Modell gewinnt, sondern das Modell mit dem besten Fit zum Geschäftsprozess.
Fazit: Die beste Modellauswahl beginnt nicht mit dem Modell
Die passende Modellauswahl beginnt nicht mit einer Liste aktueller Modellnamen. Sie beginnt mit dem konkreten Use Case, den verarbeiteten Daten und dem notwendigen Maß an Kontrolle.
Erst wenn klar ist, welche Anforderungen an Sicherheit, Nachweisbarkeit, Betrieb und Souveränität bestehen, lässt sich sinnvoll entscheiden, welche Modellklasse geeignet ist.
Damit wird aus der Modellauswahl keine Hype-Entscheidung, sondern eine Architektur- und Governance-Entscheidung.
Takeaway der Beitragsserie „KI sicher einsetzen“ Teil 5:
Nicht das prominenteste Modell ist automatisch die beste Wahl. Entscheidend ist, welches Setup den konkreten Use Case sicher, steuerbar und wirtschaftlich unterstützt.
Im nächsten und letzten Teil der Serie führen wir die bisherigen Erkenntnisse zusammen und zeigen, wie Unternehmen KI strategisch, steuerbar und skalierbar im Unternehmen verankern können.