
Im ersten Teil der Serie wurde deutlich, dass klassischer Datenschutz allein nicht mehr ausreicht, um den Einsatz von KI sicher zu gestalten. Doch selbst wenn klar geregelt ist, welche Daten verwendet werden dürfen, bleibt eine zentrale Frage offen: Wer hat eigentlich die Kontrolle über die Systeme, in denen diese Daten verarbeitet werden?
Genau an diesem Punkt setzt das Thema Souveränität im KI-Betrieb an. Es beschreibt, inwieweit Unternehmen nachvollziehen, steuern und beeinflussen können, was mit ihren Daten, den eingesetzten Modellen und den daraus entstehenden Ergebnissen geschieht.
Damit verschiebt sich die Perspektive erneut. Es geht nicht mehr nur darum, den Umgang mit Daten zu regeln, sondern darum zu verstehen, in welchem Systemkontext diese Daten verarbeitet werden und wer diesen Kontext tatsächlich kontrolliert.
Dieser Beitrag zeigt, warum Souveränität im KI-Betrieb zur zentralen Voraussetzung für sicheren KI-Einsatz wird, welche Dimensionen dabei eine Rolle spielen und welche Fragen Unternehmen frühzeitig klären müssen, um Kontrolle über ihre KI-Systeme zu behalten.
KI-Nutzung führt oft unbemerkt zum Verlust von Kontrolle
Die Nutzung von KI wirkt im Alltag meist unkompliziert. Ein Tool wird geöffnet – etwa ein Chatfenster wie ChatGPT –, ein Prompt eingegeben, zum Beispiel „Kannst du mir diese E-Mail besser formulieren?“, und innerhalb weniger Sekunden liegt ein Ergebnis vor, das direkt für die weitere Kommunikation genutzt werden kann. Für viele Nutzerinnen und Nutzer fühlt sich das kaum anders an als die Verwendung klassischer Software.
Im Hintergrund laufen jedoch deutlich komplexere Prozesse ab, wie Abbildung 1 verdeutlicht. Nachdem eine Anfrage eingegeben und abgeschickt wurde, wird sie zunächst geprüft und aufbereitet. Anschließend wird sie mit zusätzlichem Kontext angereichert und von einem Modell verarbeitet, um daraus ein Ergebnis zu erzeugen. Sowohl Eingaben als auch Ergebnisse können dabei Sicherheits- und Richtlinienprüfungen durchlaufen. Die generierte Antwort wird anschließend in eine verständliche Form gebracht und ausgegeben. Je nach System können Ein- und Ausgaben zudem gespeichert und in bestimmten Fällen zur Verbesserung von Systemen oder zur Anpassung von Modellen weiterverwendet werden.
Für die Nutzenden bleibt dieser Ablauf in der Regel unsichtbar. Genau darin liegt die Herausforderung. Mit jeder Nutzung eines KI-Tools wird ein Teil der Kontrolle abgegeben, ohne dass dies bewusst wahrgenommen wird.
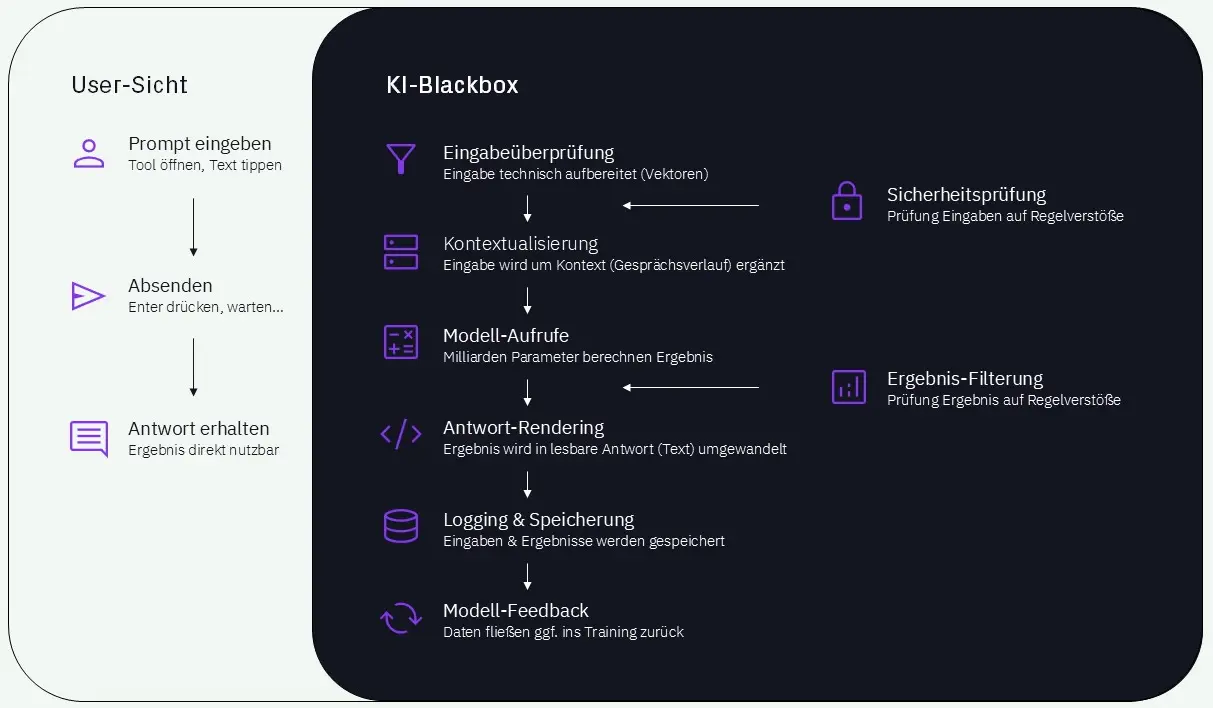
Abbildung 1: Vereinfachte Darstellung von Nutzerinteraktion und Verarbeitungsschritten eines KI-System
Besonders relevant wird das bei extern betriebenen Lösungen. Wird beispielsweise ein frei zugängliches Tool wie ChatGPT im Browser oder ein Copilot in einer Cloud-Anwendung genutzt, werden Inhalte im Hintergrund an externe Systeme übertragen und dort verarbeitet. Im Gegensatz dazu laufen interne Lösungen – etwa in der eigenen IT-Infrastruktur oder in kontrollierten Unternehmensumgebungen – innerhalb des eigenen Zugriffsbereichs.
Unternehmen haben bei externen Tools oft nur begrenzten Einblick, wo Daten landen, wie lange sie gespeichert bleiben oder wer darauf zugreifen kann.
Damit entsteht eine neue Form der Abhängigkeit, die sich nicht mehr allein mit klassischen IT-Outsourcing-Fragen vergleichen lässt.
Souveränität geht über den reinen Datenschutz hinaus
Vor diesem Hintergrund wird deutlich, dass Souveränität im KI-Kontext mehr umfasst als klassische Sicherheitsfragen. Es reicht nicht aus zu wissen, dass Daten geschützt sind. Entscheidend ist vielmehr, ob Unternehmen in der Lage sind, die Systeme selbst zu verstehen, zu steuern und im Zweifel einzugreifen.
Dabei lassen sich vier Bereiche unterscheiden, in denen Unternehmen verstehen und kontrollieren müssen, was mit ihren Daten und Systemen passiert.
1. Datensouveränität
Unternehmen müssen nachvollziehen können, welche Daten verwendet werden, wo sie gespeichert sind und wer Zugriff darauf hat. Diese Perspektive knüpft noch am stärksten an klassische Datenschutzfragen an, reicht jedoch allein nicht aus.
2. Modellsouveränität
Hier steht die Frage im Mittelpunkt, welches Modell eingesetzt wird, wie es funktioniert und inwieweit es beeinflusst oder eingeschränkt werden kann. Gerade bei externen Lösungen bleibt dieser Aspekt oft eine Black Box.
3. Betriebssouveränität
Sie beschreibt, wo und wie ein System tatsächlich läuft, wer es betreibt und ob ein Unternehmen im Zweifel die Möglichkeit hat, den Betrieb zu kontrollieren oder zu stoppen.
4. Entscheidungssouveränität
Wenn KI-Systeme in Prozesse eingreifen oder Entscheidungen vorbereiten, muss klar sein, wie stark diese Systeme wirken, wo menschliche Kontrolle erhalten bleibt und wer die Verantwortung für Ergebnisse trägt.
Diese Perspektive ist vor allem deshalb wichtig, weil sie die Debatte aus der reinen Datenschutz-Perspektive herauslöst. Souveränität ist kein Spezialthema für einzelne Funktionen wie Legal, IT-Architektur oder Security, sondern eine Frage, wie das gesamte Unternehmen KI steuert.
In der Praxis zeigt sich dabei schnell, dass zentrale Fragen oft unbeantwortet bleiben – etwa wer Datenflüsse kontrolliert, wer Verantwortung für Ergebnisse trägt oder wie abhängig ein Unternehmen von einzelnen Anbietern wird. Fehlt diese Klarheit, wird der KI-Betrieb schwer steuerbar.
Erst klare interne Regeln schaffen echte Steuerbarkeit
Um Souveränität im KI-Betrieb herzustellen, braucht es zunächst klare interne Spielregeln. Ohne diese bleibt der Einsatz von KI unsystematisch und schwer kontrollierbar.
Data Governance
Unternehmen müssen festlegen, welche Arten von Daten es gibt, wer dafür verantwortlich ist und wo sie verwendet werden dürfen. Nur so ist klar, welche Inhalte bedenkenlos in KI-Tools genutzt werden können und welche geschützt bleiben müssen.
AI Governance
Darüber hinaus braucht es klare Vorgaben, welche Anwendungen genutzt werden dürfen, wie Risiken bewertet werden und an welchen Stellen Menschen eingreifen müssen. Nicht jede Anwendung braucht die gleichen Regeln, aber jede braucht einen klaren Rahmen.
Ownership und Nutzung von Inhalten
Sobald Mitarbeitende mit internen Dokumenten, Know-how, Code oder angepassten Modellen gearbeitet wird, muss geklärt sein, wem die entstehenden Ergebnisse gehören und wer sie weiterverwenden darf.
Unabhängigkeit und Steuerbarkeit
Unternehmen sollten außerdem früh überlegen, wie abhängig sie von einzelnen Tools oder Anbietern werden wollen. Wichtig ist, ob Systeme gewechselt werden können und wie flexibel der Einsatz bleibt. Souveränität bedeutet nicht, alles selbst zu betreiben, sondern bewusst zu entscheiden, wo Abhängigkeiten akzeptabel sind.
Gesetzliche Vorgaben machen Kontrolle im KI-Betrieb zur Pflicht
Parallel zu den internen Anforderungen wird auch der regulatorische Rahmen konkreter. Mehrere europäische Regelwerke machen deutlich, dass Souveränität nicht nur eine interne Entscheidung bleibt.
Die DSGVO bildet weiterhin die Grundlage für den Umgang mit personenbezogenen Daten. Mit dem Einsatz von KI gewinnt sie zusätzlich an Bedeutung, da neue Formen der Datenverarbeitung entstehen.
Der EU AI Act verfolgt einen risikobasierten Ansatz und bringt schrittweise verbindliche Anforderungen mit sich. Erste Regelungen gelten bereits, weitere werden folgen. Für Unternehmen bedeutet das vor allem, dass Nachvollziehbarkeit, Risikobewertung und klare Verantwortlichkeiten stärker in den Fokus rücken.
Auch der Data Act verschärft die Anforderungen, insbesondere in Bezug auf Datenverfügbarkeit, Portabilität und Wechselmöglichkeiten. Damit wird die Frage, wie abhängig ein Unternehmen von einzelnen Anbietern ist, auch regulatorisch relevanter.
Ergänzend dazu erhöht NIS2 den Druck auf Risikomanagement und organisatorische Verantwortung. Gerade für kritische oder wichtige Einrichtungen stellt sich damit zunehmend die Frage, wie kontrolliert der eigene KI-Betrieb tatsächlich ist.
Checkliste: Fünf Fragen, die jede Organisation für einen sicheren KI-Betrieb beantworten sollte
Für Entscheiderinnen und Entscheider lässt sich Souveränität auf fünf Fragen verdichten:
- Wer kontrolliert unsere Daten – technisch, organisatorisch und rechtlich?
- Wer kontrolliert Modelle, Zugriffe und Änderungspfade?
- Wer darf eingreifen, wenn ein System falsche oder riskante Ergebnisse erzeugt?
- Wie weisen wir gegenüber Audits, Kundinnen oder Aufsicht nach, dass unser KI-Betrieb kontrolliert ist?
- Wie abhängig sind wir von einem Anbieter, wenn der Use Case geschäftskritisch wird?
Alle fünf Fragen sind Managementfragen, keine reinen Technikfragen. Sie berühren Investitionen, Geschwindigkeit, Verantwortlichkeiten und strategische Handlungsfähigkeit.
Fazit: Souveränität schafft die Grundlage für Kontrolle und damit für sicheren KI-Betrieb
Souveränität steht nicht im Widerspruch zu Innovation. Sie ist die Voraussetzung dafür, KI dauerhaft, kontrolliert und skalierbar einzusetzen.
Ohne klare Steuerung lassen sich Anwendungen zwar schnell umsetzen, gleichzeitig steigen jedoch Abhängigkeiten, Unsicherheiten und Nachweisprobleme – und verstärken sich mit wachsender Nutzung.
Souveränität macht den KI-Einsatz damit erst steuerbar. Sie schafft die Grundlage, um Daten, Systeme und Entscheidungen auch dann unter Kontrolle zu behalten, wenn KI tief in Prozesse integriert ist.
Takeaway der Beitragsserie „KI sicher einsetzen“ Teil 2:
Souveränität entscheidet darüber, ob KI kontrollierbar bleibt oder zur Black Box wird. Sie ist das Ergebnis bewusster Entscheidungen zu Daten, Systemen und Verantwortung und muss aktiv gestaltet werden.
In dem nächsten
Teil
der Serie "KI sicher einsetzen" (3/6) geht es darum, wie Infrastruktur-Entscheidungen konkret darüber bestimmen,
wie sicher und souverän KI betrieben werden kann.