
Im dritten Teil der Serie wurde deutlich, dass Infrastruktur im KI-Kontext kein technisches Detail ist. Sie bestimmt, wo Daten verarbeitet werden, wer Zugriff hat und wie gut Unternehmen ihre Systeme steuern können.
Entscheidend ist jetzt, wie diese Infrastruktur konkret genutzt und betrieben wird.
In vielen Diskussionen wird dabei schnell von „der Cloud“ gesprochen. Oft klingt es so, als gäbe es nur zwei Möglichkeiten: KI aus der Cloud nutzen oder alles selbst im eigenen Rechenzentrum betreiben. Diese Gegenüberstellung greift jedoch zu kurz.
Gerade bei KI gibt es nicht das eine Cloud-Modell. Vielmehr existiert ein Spektrum unterschiedlicher Betriebsformen von der einfachen API-Nutzung über souveränere Cloud-Modelle bis hin zu vollständig selbst betriebenen Private-Cloud- oder On-Premises-Setups.
Dieser Beitrag zeigt, welche Betriebsmodelle Unternehmen unterscheiden sollten, welche Vor- und Nachteile damit verbunden sind und warum die passende Wahl immer vom konkreten Use Case abhängt.
Warum „Cloud“ als Begriff zu ungenau ist
Wenn Unternehmen sagen, sie wollen KI „in der Cloud“ nutzen, kann damit sehr Unterschiedliches gemeint sein.
Manche meinen damit einfach die Nutzung eines KI-Modells über eine Schnittstelle (API).
Andere betreiben eigene Anwendungen oder Modelle, nutzen dafür aber die Infrastruktur großer Cloud-Anbieter. Wieder andere sprechen über europäische Datenhaltung, souveräne Cloud-Varianten oder vollständig europäische Anbieterstrukturen.
Für die Bewertung eines KI-Setups reicht es deshalb nicht aus, nur zu fragen, ob etwas „Cloud“ ist oder nicht. Entscheidend sind vielmehr mehrere Fragen:
- Wer betreibt die Infrastruktur?
- Wo werden Daten verarbeitet und gespeichert?
- Welcher Rechtsraum gilt?
- Wer hat administrativen Zugriff?
- Wie stark lässt sich das Setup anpassen?
- Wie hoch ist der eigene Betriebsaufwand?
Erst diese Unterscheidung macht sichtbar, wie viel Kontrolle ein Unternehmen tatsächlich hat.
Sechs Betriebsmodelle für KI im Überblick
Um die Unterschiede greifbar zu machen, hilft ein Blick auf die verschiedenen Betriebsmodelle im Vergleich.
Abbildung 1 ordnet diese entlang von zwei zentralen Dimensionen ein: dem Grad der Kontrolle und dem notwendigen Betriebsaufwand. Dadurch wird sichtbar, wie unterschiedlich die einzelnen Ansätze ausgestaltet sind und welche Vor- und Nachteile jeweils bestehen.
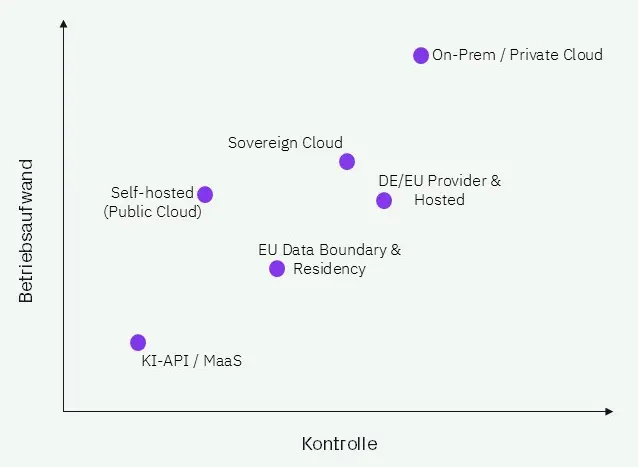
Abbildung 1: KI-Betriebsmodelle entlang der Achsen Kontrolle und Betriebsaufwand
Im Folgenden werden die wichtigsten Betriebsmodelle im Überblick dargestellt:
1. KI-API / Model as a Service
Der einfachste Einstieg erfolgt über sogenannte Model-as-a-Service-Angebote. Dabei werden KI-Modelle über Schnittstellen genutzt, während Infrastruktur, Betrieb und Skalierung vollständig beim Anbieter liegen.
Der Vorteil liegt auf der Hand: Unternehmen können sehr schnell starten, ohne eigene Infrastruktur aufzubauen. Gerade für erste Experimente oder weniger kritische Anwendungsfälle kann das sinnvoll sein.
Gleichzeitig liegt der Kontrollpunkt weitgehend außerhalb des Unternehmens. Daten werden an externe Systeme übergeben, die Verarbeitung findet außerhalb des eigenen Betriebs statt und die Nachvollziehbarkeit bleibt begrenzt.
Typische Beispiele sind die Nutzung von OpenAI, Google Gemini oder Anthropic Claude über APIs.
2. Self-hosted in der Public Cloud
Bei diesem Modell betreiben Unternehmen Anwendungen oder Modelle selbst, nutzen dafür aber die Infrastruktur eines großen Cloud-Anbieters.
Dadurch entsteht mehr Kontrolle als bei einer reinen API-Nutzung. Datenflüsse, Logging und Sicherheitsmechanismen lassen sich stärker gestalten. Gleichzeitig bleibt die zugrunde liegende Infrastruktur weiterhin beim Cloud-Anbieter.
Dieses Modell kann sinnvoll sein, wenn Unternehmen mehr technische Steuerung benötigen, aber keine eigene Infrastruktur aufbauen wollen.
3. EU Data Boundary / Data Residency
Bei Data-Residency-Modellen steht der Datenstandort im Mittelpunkt. Daten werden innerhalb bestimmter geografischer Grenzen verarbeitet oder gespeichert, zum Beispiel innerhalb der EU.
Das ist ein wichtiger Baustein für Compliance. Dennoch löst der Datenstandort allein nicht alle Kontrollfragen. Auch wenn Daten in der EU liegen, kann der Betreiber weiterhin ein globaler Anbieter sein. Zugriffsrechte, Betriebslogik und Abhängigkeiten bleiben deshalb weiterhin relevant.
4. Sovereign Cloud
Sovereign-Cloud-Modelle gehen über den reinen Datenstandort hinaus. Sie betrachten zusätzlich Betrieb, Zugriff und Governance.
In vielen Fällen wird dabei Technologie großer Plattformanbieter genutzt, während der Betrieb stärker über lokale oder europäische Partner abgesichert wird. Dadurch entsteht ein Mittelweg zwischen Skalierbarkeit und zusätzlicher Kontrolle.
Dieses Modell kann für Unternehmen interessant sein, die moderne Cloud-Funktionen nutzen möchten, aber höhere Anforderungen an Kontrolle, Nachweisbarkeit und regulatorische Anschlussfähigkeit haben.
5. DE/EU Provider & Hosted
Bei europäischen Hosting- und Cloud-Anbietern liegen Infrastruktur und Betrieb ausschließlich im europäischen Rechtsraum.
Im Vergleich zu Sovereign-Cloud-Modellen wird die Abhängigkeit von globalen Plattformanbietern komplett vermieden. Für Unternehmen kann das besonders dann relevant sein, wenn Datenschutz, regulatorische Anforderungen oder politische Unabhängigkeit stärker gewichtet werden als maximale Plattformtiefe oder neueste Hyperscaler-Funktionen.
Beispiele sind Anbieter wie STACKIT, Open Telekom Cloud oder entsprechende europäische Hosting-Modelle.
6. On-Premises / Private Cloud
Die höchste Kontrollstufe bietet der vollständige Eigenbetrieb. Infrastruktur, Modelle und Anwendungen laufen im eigenen Rechenzentrum oder in einer dedizierten Private-Cloud-Umgebung.
Damit bleiben Daten, Zugriffe und Betrieb vollständig im eigenen Einflussbereich. Gleichzeitig steigen Aufwand und Verantwortung deutlich. Betrieb, Wartung, Sicherheitsupdates, Kapazitätsplanung und Monitoring müssen selbst beherrscht werden.
Mehr Kontrolle bedeutet also nicht automatisch weniger Risiko. Sie muss auch organisatorisch und technisch umgesetzt werden können.
Warum diese Unterschiede zwischen den einzelnen Betriebsmodellen auch strategisch relevant sind, zeigt ein Blick auf die verfügbare Infrastruktur.
Europa macht Fortschritte, bleibt bei Rechenkapazität aber deutlich hinter den USA und China zurück.
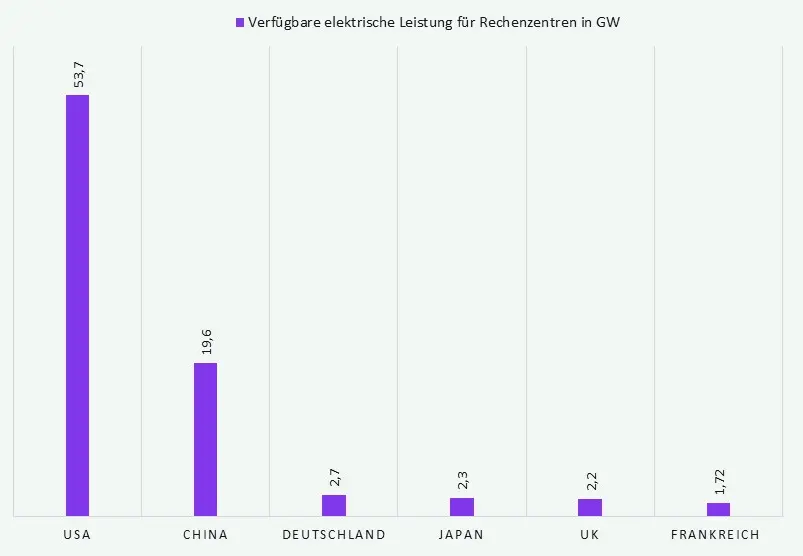
Abbildung 2: Einordnung der globalen Data-Center- und Cloud-Kapazitäten (Stand: Februar 2026)
Das bedeutet: KI-Betriebsmodelle sind nicht nur eine Architekturfrage. Sie hängen auch davon ab, welche Kapazitäten verfügbar sind, wie stark Unternehmen von Anbietern abhängig sind und welche souveränen Optionen tatsächlich realistisch umsetzbar sind.
Typische Fehlannahmen bei KI-Betriebsmodellen
In der Diskussion rund um KI-Betrieb halten sich einige Annahmen, die in der Praxis so nicht tragen.
Eine davon lautet: Wenn Daten in der EU liegen, ist das Thema gelöst. Das greift zu kurz. Der Datenstandort ist wichtig, beantwortet aber nicht automatisch die Frage, wer Zugriff hat, wer das System betreibt und wie im Ernstfall eingegriffen werden kann.
Eine zweite Annahme ist: On-Premises ist grundsätzlich sicherer. Auch das stimmt so nicht. Mehr Kontrolle bedeutet nur dann mehr Sicherheit, wenn Betrieb, Überwachung und Absicherung entsprechend umgesetzt werden.
Und schließlich gilt: Eine einfache API-Lösung ist nicht automatisch die falsche Wahl. Für unkritische Inhalte, erste Tests oder klar abgegrenzte Anwendungsfälle kann sie durchaus sinnvoll sein – solange Daten, Risiko und Governance dazu passen.
Welches Modell passt zu welchem Use Case?
Nicht jeder KI-Anwendungsfall braucht dasselbe Betriebsmodell.
Ein Marketing-Team, das mit unkritischen Texten experimentiert, hat andere Anforderungen als eine Compliance-Abteilung, die sensible Vertragsdokumente verarbeitet. Ein interner Wissensassistent mit pseudonymisierten Inhalten braucht möglicherweise weniger Kontrolle als ein System, das mit Source Code, Forschungsunterlagen oder hochsensiblen Kundendaten arbeitet.
Als Orientierung gilt:
- Geschwindigkeit und einfache Erprobung sprechen eher für API- oder schlanke Cloud-Modelle.
- Eine Balance aus Kontrolle und Skalierung spricht eher für kontrollierte Cloud- oder Sovereign-Cloud-Ansätze.
- Maximale Nachweisbarkeit und Datenkontrolle sprechen eher für Private-Cloud- oder On-Premises-Modelle.
Die zentrale Frage lautet deshalb nicht: Cloud oder nicht
Cloud?
Sondern: Welches Betriebsmodell passt zu Daten, Risiko, Kontrollbedarf und
Zielbild des konkreten Use Case?
Fazit: Die Betriebsform entscheidet über Kontrolle, Aufwand und Nachweisbarkeit
Cloud ist nicht gleich Cloud. Zwischen einfacher API-Nutzung, europäischer Datenhaltung, souveränen Betriebsformen und vollständigem Eigenbetrieb liegen große Unterschiede.
Diese Unterschiede entscheiden darüber, wie viel Kontrolle ein Unternehmen tatsächlich hat, wie gut sich Anforderungen nachweisen lassen und wie hoch der eigene Betriebsaufwand wird.
Wer diese Modelle sauber unterscheidet, führt keine ideologische Cloud-Debatte, sondern trifft eine bewusste Architekturentscheidung.
Takeaway der Beitragsserie „KI sicher einsetzen“ Teil 4:
Nicht der Begriff „Cloud“ ist entscheidend, sondern die konkrete Betriebsform. Sie bestimmt, wie viel Kontrolle, Nachweisbarkeit und Aufwand ein Unternehmen für einen KI-Use-Case tatsächlich hat.
Im nächsten Teil geht es darum, wie Unternehmen aus Datenanforderungen und Kontrollbedarf eine konkrete Entscheidung für Setup und Modellauswahl ableiten können.